How SCOUTS works¶
Interface elements¶
This section explains what every button and option of the SCOUTS interface does.
Main window¶
These are the elements of the main window:
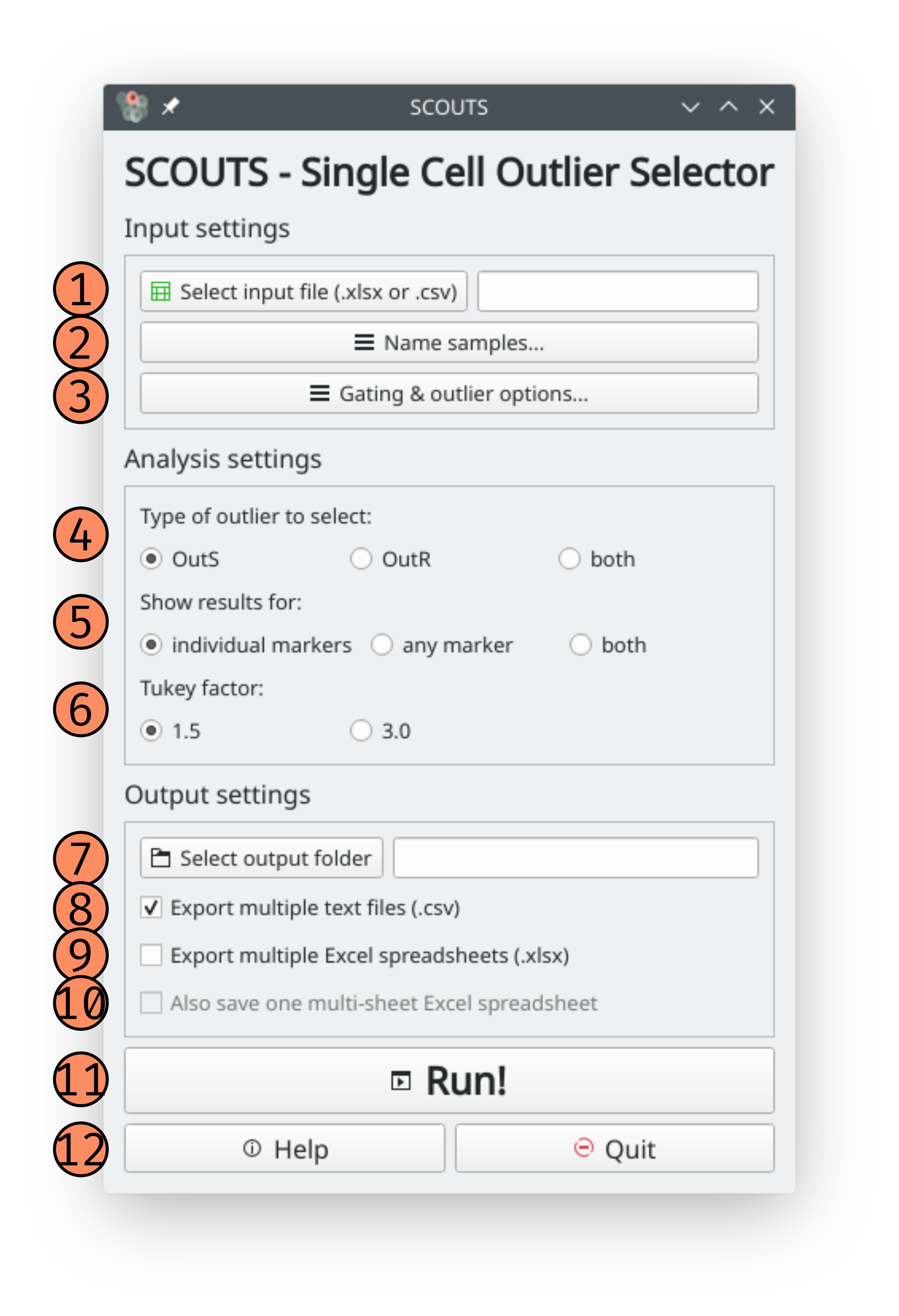
1) Input file: select your input file by clicking on this button. Valid input file formats are Excel spreadsheets (.xlsx) and comma-separated values (.csv). Please be sure that the input file is properly formatted.
2) Name Samples: this opens the sample names window.
3) Gating & outlier options: this opens the gating window.
4) Type of outlier to select: here you can select which cutoff value to consider when selecting outliers.
- Outliers by sample (OutS): SCOUTS will calculate the cutoff value for each sample independently. In other words, the point from which a given cell is considered outlier will be different in different samples, since each sample has its own distribution of values.
- Outliers by reference (OutR): SCOUTS will calculate the cutoff value for an user-defined reference sample, and use this value when selecting outliers for the remaining samples. This is useful to compare outliers from different samples using the same baseline for comparisons (e.g. “how many outliers do the treatment samples have, compared to the control sample and using the same cutoff point?”).
- both: SCOUTS performs both analyses for OutS and OutR separately.
5) Show results for: here you can select how SCOUTS considers when a cell is an outlier or not.
- Individual markers: SCOUTS will find outliers for each marker present in the input file. Each marker generates its own output file, where only cells that are outliers for that specific marker are present
- Any marker: SCOUTS will find outliers for at least one marker present in the input file. The output file contains all cells that are considered outliers for at least one of the markers.
- both: SCOUTS performs both analyses for individual markers and any markers separately.
6) Tukey factor: choose whether to consider 1.5 or 3.0 as the Tukey factor for calculating outliers. Conceptually, a Tukey factor of 1.5 selects possible outliers, while a Tukey factor of 3.0 selects probable outliers.
7) Select output folder: the base folder in which to save all results from SCOUTS. We recommend creating a new folder, in order to keep files organized. Be aware that saving multiple SCOUTS analyses to the same output folder will likely result in your data being overwritten, so use different folders for different runs! Here is a detailed description of the files that SCOUTS outputs.
8) Export csv: this option generates comma-separated values (.csv) files for the outliers for each marker/sample combination.
9) Export Excel: this option generates Excel spreadsheet (.xlsx) files for the outliers for each marker/sample combination.
10) Generate multi-sheet Excel: this option generates one large Excel workbook, where all Excel spreadsheets generated are joined in the same file. This option is included for users that want to have all analyses on a single file. Be aware that this option consumes a lot of RAM, and may slow your computer down, so be sure that your machine can handle it!
11) Run: click here to start SCOUTS. The button cannot be clicked again while SCOUTS is running (although you can still cancel SCOUTS by closing the program). Once SCOUTS has finished, a message box will appear informing you when that the analysis is done.
12) Help & Quit: used to open the online documentation and to exit SCOUTS.
Sample names window¶
In this window, the user must choose what samples to analyse. It is crucial that sample names are present in the first column of your input data.
These are the elements of the sample names window:
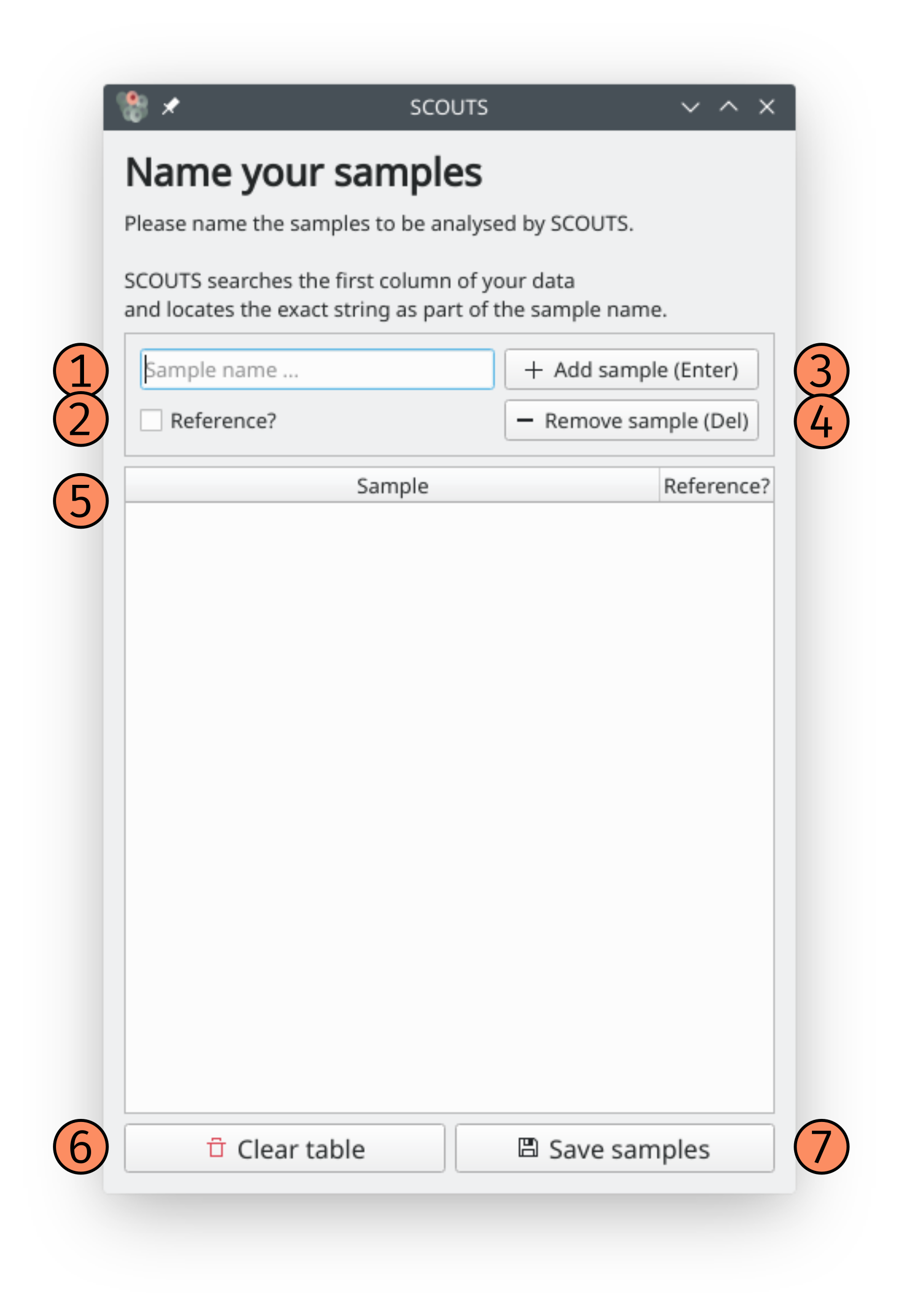
1) Sample name: type your sample name here.
2) Reference checkbox: check this box to mark the sample in the box above as the reference sample, for OutR selection.
3) Add sample: click here to add the sample to the list (shortcut: Enter).
4) Remove sample: click here to remove a highlighted sample from the list (shortcut: Delete).
5) Sample table: this table keeps track of all samples, and which sample is the reference (if any).
6) Clear table: click this button to clear all samples from the table.
7) Save samples: click this button to accept the names in the sample table and go back to the main window.
Gating window¶
In this window, users can choose whether to apply gating to cells before running SCOUTS, and to generate output for different cell populations.
These are the elements of the gating window:
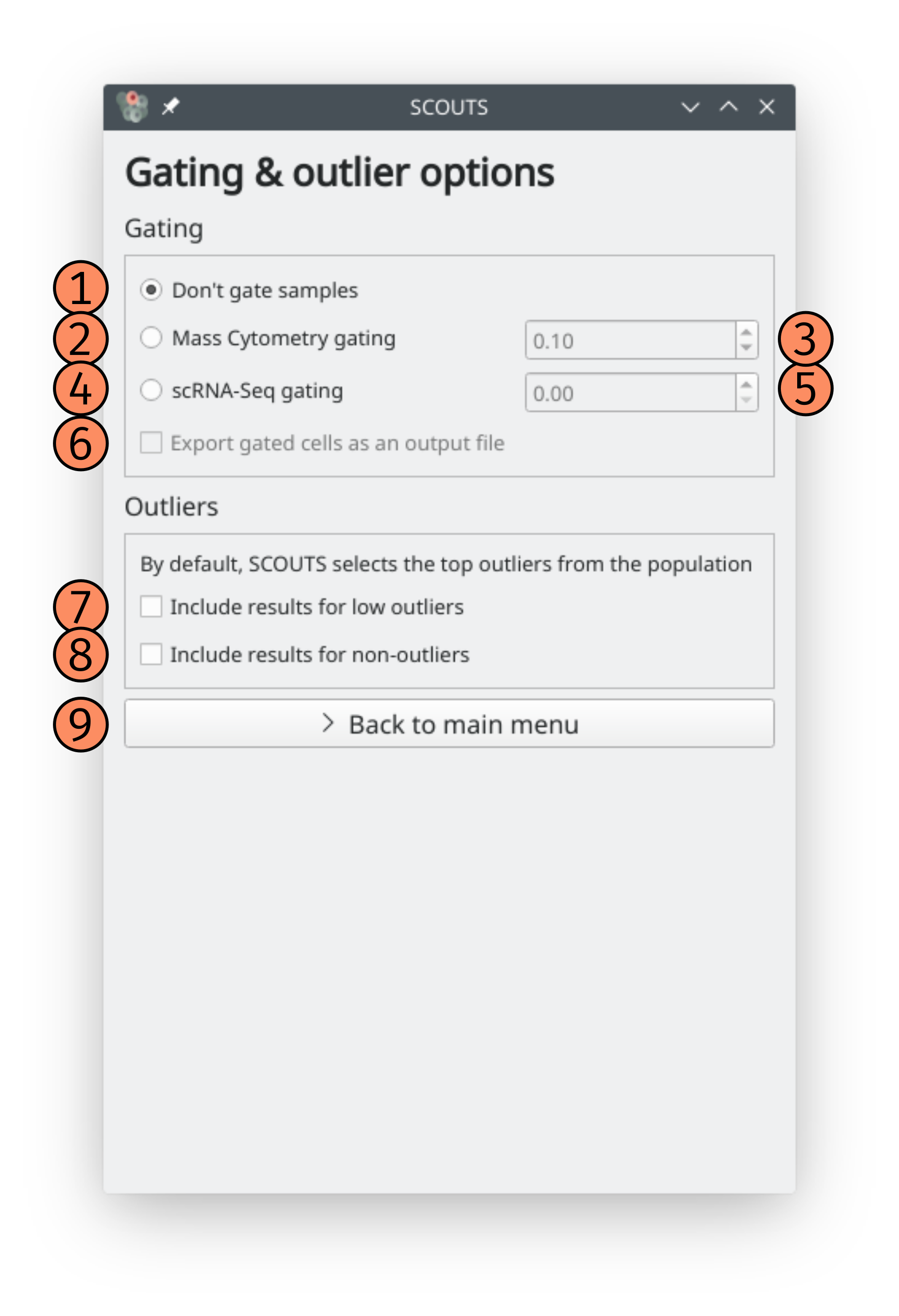
1) No gating: do not gate your input data. This is the default option.
2) Mass cytometry gating: this gating option aims to exclude poorly stained cells from a mass cytometry experiment. Cells that have an average row expression lower than the gating value will be excluded.
3) Mass Cytometry gating value: the value to use for mass cytometry gating. Only applies if mass cytometry gating is active.
4) Gate scRNA-Seq: this gating option aims to exclude cells with low read counts. Cells that have an read count for a given marker smaller or equal to the gating value will not contribute for the cutoff value of that marker. Additionally, a cell that has all markers below the gating value will be excluded.
5) scRNA-Seq gating value: the number of reads to use for scRNA-Seq gating. Only applies if scRNA-Seq gating is active.
6) Export gated cells: select this option to generate an extra output file (.xlsx) that’s identical to your input file, except for the absence of the gated cells.
7) Include results for low outliers: select this option to also generate output for low outliers, i.e. cells that are outliers because of their low expression profile.
8) Include results for non-outliers: select this option to also generate output for non-outliers, i.e. cells that are not outliers because their expression profile is not too high nor too low.
9) Back to main menu: click this button to go back to the main window, saving current gate settings.
How SCOUTS selects outliers¶
SCOUTS treats each marker/sample combination as being a subpopulation, and calculates the first quartile (Q1) and third quartile (Q3) for this subpopulation.
The cutoff value for each marker/sample combination is, in turn, calculated using Tukey’s fences:
upper cutoff = Q3 + (IQR * t)
lower cutoff = Q1 - (IQR * t)
where IQR is the interquartile range (Q3 - Q1) and t is the Tukey factor.
The quantiles are calculated by linear interpolation. See the Pandas documentation on quantiles to learn more about this.
Having the cutoff value from each marker/sample combination, SCOUTS proceeds to select cells from the input table with expression values higher than the upper cutoff (top outliers), lower than the lower cutoff (for bottom outliers) or in between (for non-outliers).
Depending on user choice, outliers for each marker may be selected, or outliers for at least one marker. Additionally, the cutoff value used may come from a reference sample (OutR) or from each sample itself (OutS).
About input files¶
The input file for SCOUTS should have:
- a header containing all markers. This is the first line of a .csv file, or the first row of an Excel spreadsheet;
- Cell ID in the first (leftmost) column. This is the field that SCOUTS uses to search for sample names, so each cell ID must have a name that conveys from which sample it belongs to;
- expression values of cell ID x marker, for all other positions in the input data.
Deviations from these rules will likely result in a failed/error-prone analysis.
About sample names¶
When starting the analysis, SCOUTS divides the input data into samples. SCOUTS searches for each sample (i.e. each name in the sample table) in the first column of the input data. Sample names are case-sensitive, so be sure to type them correctly.
SCOUTS will throw explicit errors if you:
- try to run the program with an empty sample list;
- try to perform OutR analysis with no reference sample;
- none of the sample names are found in the first column of the input data.
SCOUTS will not stop the analysis nor warn you if:
- some, but not all sample names are found in the first column of the input data (these sample names will be ignored).
- a given sample name appears in more than one subset of samples (these cells will be analysed twice).
- some cells do not belong to any sample (these cells will be ignored)
Make sure to use sample names that are unique to each sample, and double-check if you have included all samples!
About output files¶
SCOUTS creates a subfolder called data in the output folder. In this folder, every file corresponds to a different subpopulation of outliers selected by SCOUTS.
Output files are organized in numerical order. The summary.xlsx spreadsheet contains the correspondence between file number and outliers selected.
SCOUTS also generates the following output files in the output folder:
stats.xlsx: contains information of number of cells, mean, median and standard deviation in the different populations selected.cutoff_values.xlsx: contains the upper and lower cutoff values for each sample x marker combination.gated_population.xlsx(optional): contains the whole gated population, prior to SCOUTSmerged_data.xlsx(optional): contains all individual Excel file indataas spreadsheets in a single Excel workbook.

